When I first had the idea to start a blog to communicate some aspects of science that I not only find fascinating, but think other people also would, DNA seemed like the obvious place to start. After all, it is the ‘building block of life’, the simple double helix that makes you unique, as well as the subject of an innumerable amount of nauseating metaphors from sports stars, proclaiming that winning is “in my DNA”.
On a famous night in 1953, 84 years after the forgotten Friedrich Miescher had discovered DNA, although he named it nuclein, James Watson and Francis Crick exclaimed to the punters of The Eagle pub in Cambridge that they had ‘solved the secret of life’, which turned out to be a double helix, not 42. Yet how many people can tell you what this simple acronym actually stands for? And why is it a double helix, and why is this important? This article will explain the basics about what makes up DNA and why it is arranged in this elegant fashion, forming what is one of the most beautiful and well recognised molecules in biology.
DNA stands for DeoxyriboNucleic Acid. Quite a mouthful, hence the handy abbreviation. It is a polymer of smaller units called nucleotides; hence, it is ‘nucleic’. Each nucleotide contains a 5 carbon sugar group (ribose), which lacks an oxygen atom (deoxy) at a key place, hence ‘deoxyribo’, a phosphate group, which is weakly acidic, hence ‘acid’, , and a base, which is actually the most important part. The result is deoxyribonucleic acid, or DNA, to save typing time. I find that biologists like long words… it makes us sound (and feel) clever.
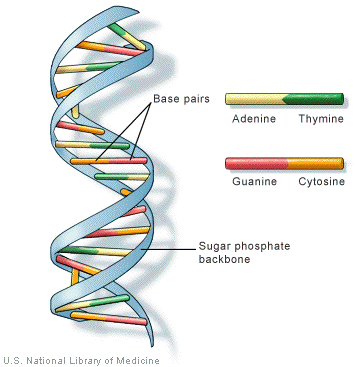
The phosphate and sugar groups are very similar to those which are ever-present in your body, cup of tea or bag of fertiliser, and these provide a solid backbone to the DNA, allowing it to hold its shape and not collapse into a nucleic acid-y mush. But the most important part of each nucleotide is the base. This is what makes up the code that defines the way we are. There are 4 bases in DNA, Adenine (A), Thymine (T), Cytosine (C) and Guanine (G), again handily abbreviated, and it is the order at which these occur within a DNA sequence that writes the code. For example, a simple piece of genetic code could read:
ATGCATGGACTAACTCCTGTTAAACCGTTCAGC…
This can go on for millions of bases, and it is this that makes up your genes and defines who you are. In fact there are 3 billion, that’s right… billion! bases in the tightly packed human genome. If this was all stretched out in a line it would have a length of 1 meter, but each cell contains 2 copies of the genome, so each tiny cell has 2 m of DNA squashed up inside it in the form of chromosomes. If all of the DNA in your body was stretched out like this it would reach the sun and back… 50 times!
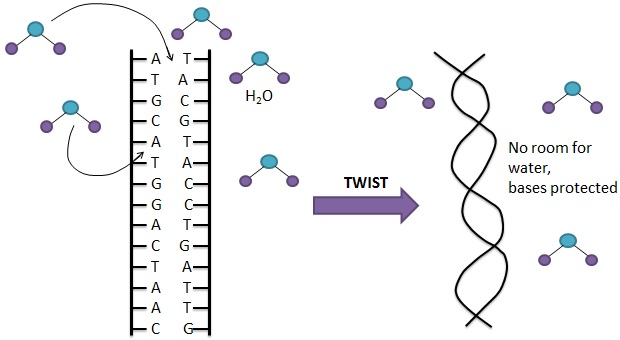
So if the DNA is formed of a series of bases in a long line, why is it a double helix? This comes down to the simple fact that the bases hate water, and are described as ‘hydrophobic’. The sugar-phosphate backbone, on the other hand, loves water; it can’t get enough of it! So it is termed ‘hydrophilic’. There is a huge amount of water cursing through our body at any one time, so it appears that the hydrophobic bases are in somewhat of a predicament. To solve this conundrum, two strands of DNA squash themselves together, with the hydrophobic bases facing in and the hydrophilic sugar-phosphate backbone facing out, allowing the bases to hide from the water. But this isn’t quite enough, if they stayed in this linear position, small water molecules can squeeze through the gaps and get to the bases, so the two strands of DNA tilt themselves and twist around one another, in an anti-clockwise direction, closing the gaps, meaning the bases stay nice and dry.
The bases, however, do not always fit in this tight arrangement. Because they have to get so close to one another to exclude the water, they need to slot together very precisely, like jig-saw pieces. A and T can fit together very tightly, as can C and G, so these bases are always found in pairs, A on one strand will appear opposite a T on the other strand, as will C and G. Other matches are never seen, for example an A will never be opposite another A, C or G, as their shapes cannot sufficiently fit together. These bases then form weak interactions called hydrogen bonds, which hold the two strands together in a very stable and well-engineered structure. Clearly, this means that the two strands of DNA are not identical, in fact they are opposites of one another, and are described as being ‘complementary’. It does mean, however, that if the sequence one strand is known, the sequence of its complementary strand can be easily deduced. For example, if we look at the earlier sequence, we can write its complementary strand underneath it:
ATGCATGGACTAACTCCTGTTAAACCGTTCAGC…
TACGTACCTGATTGAGGACAATTTGGCAAGTCG…
But what does this code mean…? This post has gone on long enough, so understanding this will come later.
Hi,
I have recently started learning about DNA at university and find it interesting how recently many of the advancements have been made and how much scientists are still unsure of concerning things like DNA replication. There are still many things I want to know though.
How is a base replaced with another base that does not compliment the base on the complimentary strand? I know about mutagens, but how do they actually work. Then I have a question about the hydrogen bonds between the complimentary base pairs, wouldn’t that make them hydrophilic and cause them to form hydrogen bonds with water?
I also found some things other readers might find interesting, but it’s more on the history of the discovery of DNA as the main genetic material, which to me is pretty recent history. For a long time scientists believed that proteins were the genetic material of living organisms since it has many more possible arrangements. However, in 1952 there were experiments done that finally proved that DNA was in fact the genetic material of bacteriophages. Bacteriophages being viruses that replicate by injecting their genetic material into bacteria, which then follows that genetic material’s instructions like it’s its own.
However, the scientific community being what it is kind of ignored the Avery–MacLeod–McCarty experiment which was done 8 years earlier in 1944. Basically some bacteria incorporate genetic material from its surroundings into itself and then use it. In their experiment they removed 99% of the protein in a sample leaving only DNA which they then added to the bacteria. The sample changed the characteristics of the original bacteria when added, thus proving that the genetic material has to be DNA. Based on what I’ve been told people still hung onto their protein centred beliefs anyway for a few more years.
Good luck with the rest of your blogging,
Eygelaar, DF
U14011329